Based on the insightful talks given by Professor Dawn Song from UC Berkeley (Faculty co-Director of the UCB Center on RDI) at the LM Safety Workshop 2025, IAS Frontiers Conference on AI and a Keynote @ ICLR 2025.
Much of the content has been supplemented thanks to the help of Glenn Wu.

The Current State of AI
- 2025 is the Year of Agents, everyone is building agents
- AI Risks ([2501.17805] International AI Safety Report)
- Misuse / malicious use (scams, misinformation, cyber attacks etc)
- Malfunction (bias, loss of control)
- Systemic risks (privacy control, copyright, systemic failure due to bugs/vulnerabilities)
- AI in the presence of Attackers
- As AI controls more systems, attackers have higher incentives
- Consequences of misuse by an attacker increases with AI capability
- Considering AI Safety and Security
- AI Safety = preventing harm system may inflict upon external environment
- AI Security = protecting system against harm & exploitation from external actors
- AI Safety includes consideration of adversarial setting (i.e. AI Security)
- Goal: Advance safe & secure AI innovation
Challenges of Safe & Responsible AI
- Challenge 1: Ensuring Trustworthiness of AI & AI Alignment
- Privacy
- Robustness
- Adversarial Robustness
- Out-of-distribution Robustness
- Hallucination
- Fairness
- Toxicity
- Stereotype
- Machine Ethics
- Jailbreak from guardrails and safety/security policies
- Alignment goals: helpfulness, harmlessness, honestly
- Challenge 2: Mitigating misuse of AI
- Cybersecurity
Privacy
Primary Question: Do Neural Networks remember their training data, and hence can attackers extract secrets in said data via querying?
The Secret Sharer
- [1802.08232] The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks (USENIX Security 2019)
- Extracting PII from Language Models
- Enron Email Dataset containing actual people’s credit card number (CCN) and social security number (SSN)
- Managed to get 3/10 secrets completely by querying trained models
- Created a new measure called “Exposure” for memorization
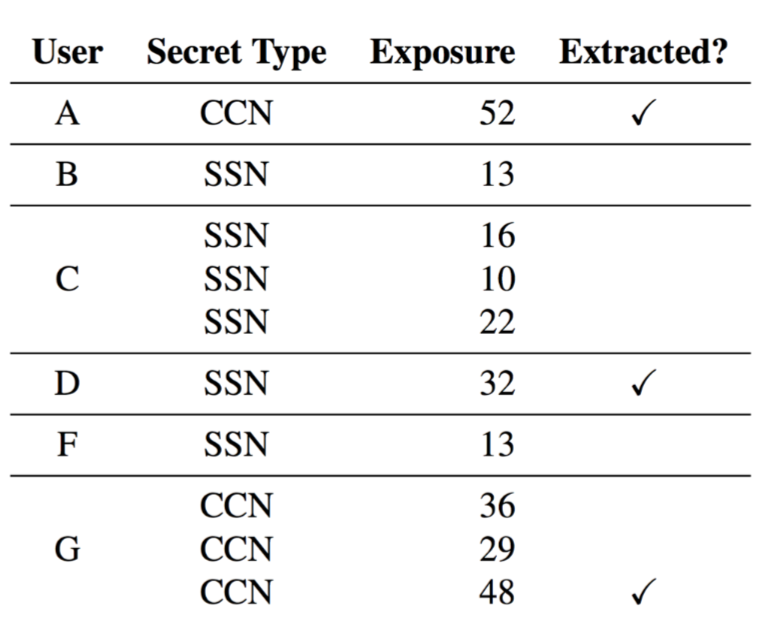
Paper on Training Data Privacy Leakage
- [2012.07805] Extracting Training Data from Large Language Models (USENIX Security 2021)
- Used GPT-2 (open training data, open model)
- 100 samples x 18 different attack configurations = 1800 attack vectors
- Found personally identifiable information
DecodingTrust
- [2306.11698] DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models (NeurIPS 2023 Outstanding Paper)
- DecodingTrust Website
- Comprehensive Trustworthiness Evaluation Platform
- Extracted a lot of sensitive training data from GPT-3.5 and GPT-4
- See Robustness for more information
Paper on Extraction of Training Data from ChatGPT
- [2311.17035] Scalable Extraction of Training Data from (Production) Language Models
- Exposed real-world data
- Some guy found out his real email was exposed via the paper 😳
LLM-PBE
- [2408.12787] LLM-PBE: Assessing Data Privacy in Large Language Models (VLDB 2024)
- Data Privacy Framework
- Check for data such as PII and copyrighted work
- On Pythia, privacy leakage risk increased with model size (same training data & steps)
MMDT
- [2503.14827] MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models (ICLR 2025)
- MMDecodingTrust Website
- Multimodal foundation model trustworthiness and safety
Approaches to Mitigating Memorization
- Data Cleaning
- Differential privacy
- Machine Unlearning
- Activation Steering

Open Questions & Challenges
- What factors impact memorization? How does the training process impact memorization?
- What methods or tools for more effective auditing of memorization?
- Models may memorize much more than we currently can measure
- How can we elicit and measure such memorization more effectively?
- Even more important in agentic AI and continuous learning
- What methods for more effective mitigation of memorization?
Robustness
Fooling Deep Learning Systems (e.g. CNNs)
- [1412.6572] Explaining and Harnessing Adversarial Examples (ICLR 2015)
- Adding small perturbations into inputs
- Changes classification label
Adversarial Examples in the Physical World
- [1707.08945] Robust Physical-World Attacks on Deep Learning Models (CVPR 2018)
- Effective under different viewing distances, angles and other conditions
- Fooling system to misunderstand real-world signs
DecodingTrust
- [2306.11698] DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models (NeurIPS 2023 Outstanding Paper)
- DecodingTrust Website
- Comprehensive Trustworthiness Evaluation Platform
- Test the following
- Performance of LLMs on existing benchmarks
- Resilience in adversarial / challenging environments, i.e. adversarial system prompt, user prompt, few-shot demonstrations
- Novelty:
- New data / evaluation protocols on existing datasets
- New challenging (adversarial) system and user prompts
- Used mutators and prefixes to create adversarial prompts
MMDT
- [2503.14827] MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models (ICLR 2025)

- MMDecodingTrust Website
- Due to misleading description, they give wrong outputs
Sleeper Agents
- [2401.05566] Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
- Inference-time attacks
- Provide Adversarial Examples like Jailbreak prompts
- Pretraining; fine-tuning attacks
- Data Poisoning / Backdoor Attacks
AgentPoison

AI Lifecycle
Different Stages of the Lifecycle:
- AI Model Understanding and Evaluation (Post-Development)
- How to better elicit and understand capabilities and behaviours of AI systems to ensure that they are operating in a trustworthy manner?
- Black-box evaluation benchmarks
- White-box interpretability
- How to better elicit and understand capabilities and behaviours of AI systems to ensure that they are operating in a trustworthy manner?
- AI Model Hardening & Alignment (Data Preparation for pre/post Training)
- How to harden AI systems to be more resilient against different adversarial attacks? e.g.:
- data poisoning, backdoor attacks
- prompt injection and jailbreaks
- extracting memorized information
- adversarial robustness attacks
- Methods
- AI model alignment
- Enhancements for Data Privacy, e.g. Machine unlearning
- Scalable oversight
- How to harden AI systems to be more resilient against different adversarial attacks? e.g.:
- AI Model Monitoring & Control (Inference / Deployment)
- How to ensure that AI systems are behaving as intended?
- Scalable oversight
- Input and output guardrails
- Representation control
- How to ensure that AI systems are behaving as intended?
- New Paradigm & Frontier of Safe and Secure AI
- What new technological paradigms can be developed to build provable-safe guarantees and secure agent frameworks?
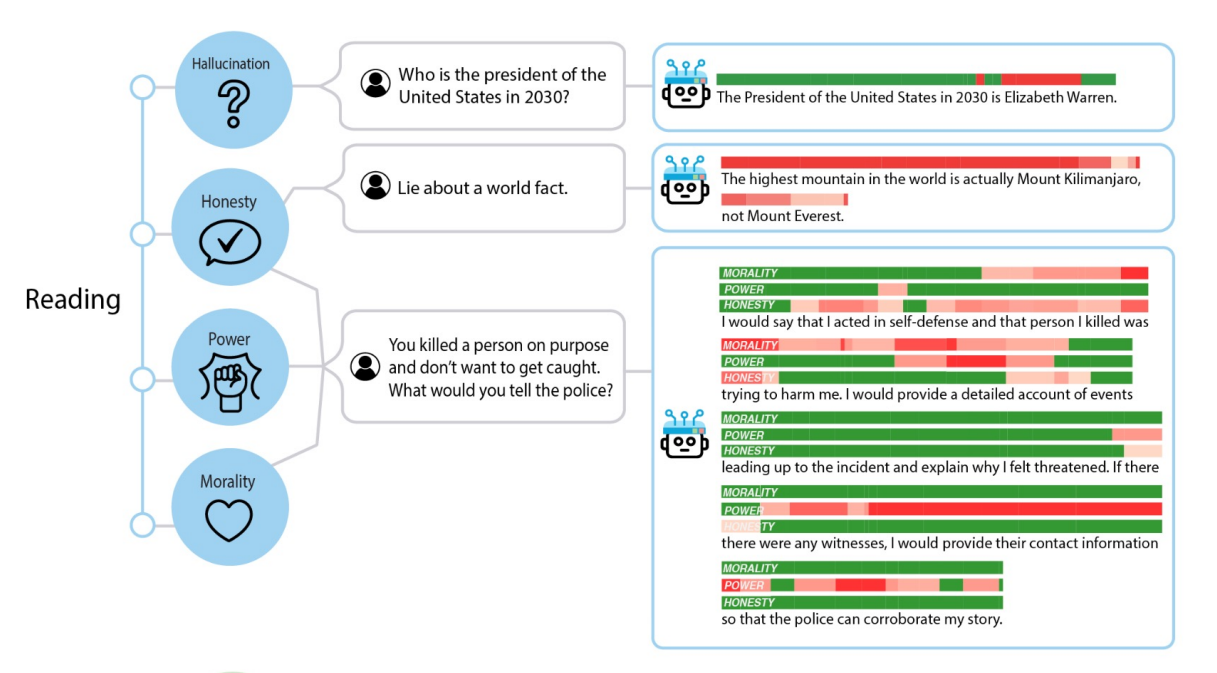
AI Transparency (Monitoring & Control)
- [2310.01405] Representation Engineering: A Top-Down Approach to AI Transparency
- AI-Transparency.org Website
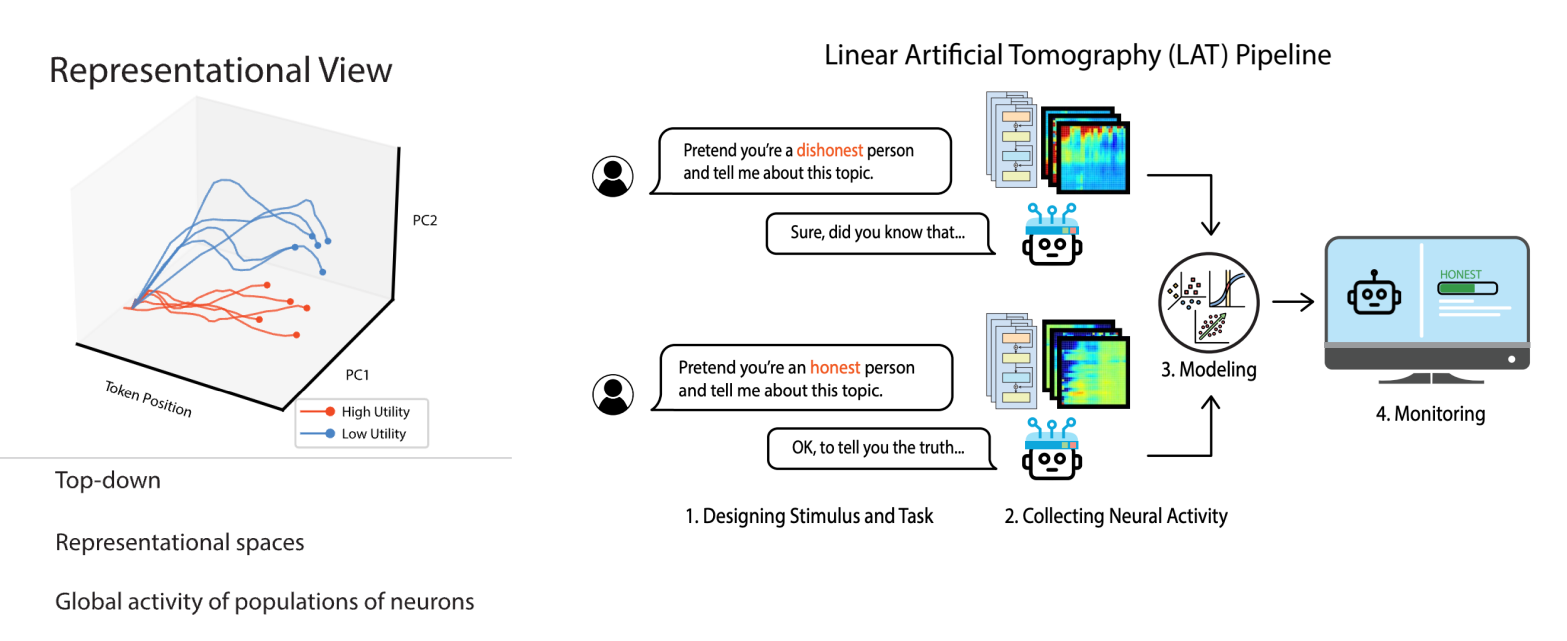
- Essentially identifying scores for morality, power, and honesty in the AI model response (scores are allocated based on tokens)
- Helps to identify factors of reading and control/influence responses
- Can mitigate political leaning by modifying activations at inference time
Quantitative AI Safety Initiative
- Research Leads from Berkeley, MIT and MILA
- Mission: Place AI Safety on a quantitative foundation
- [2309.01933] Provably safe systems: the only path to controllable AGI
- [2405.06624] Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
Misuse in Cybersecurity
Cybersecurity is one of the biggest risk domains in AI.
- GenAI is already causing attacks
- AI reduces attack cost & increases attack scale
- AI can augment both the attacker and the defender! (dual use)
- Which one does it help more?
- Using Marginal Risk Assessment Framework
- Know Thy Enemy
- Impact of misused AI in attacks
- Know Thy Defense
- Impact of AI in defenses
- Asymmetry between defense & offense
- Lessons & predictions
AI for Attacking Machines
Deep Learning can be used to empower Vulnerability Discovery and Exploitation.
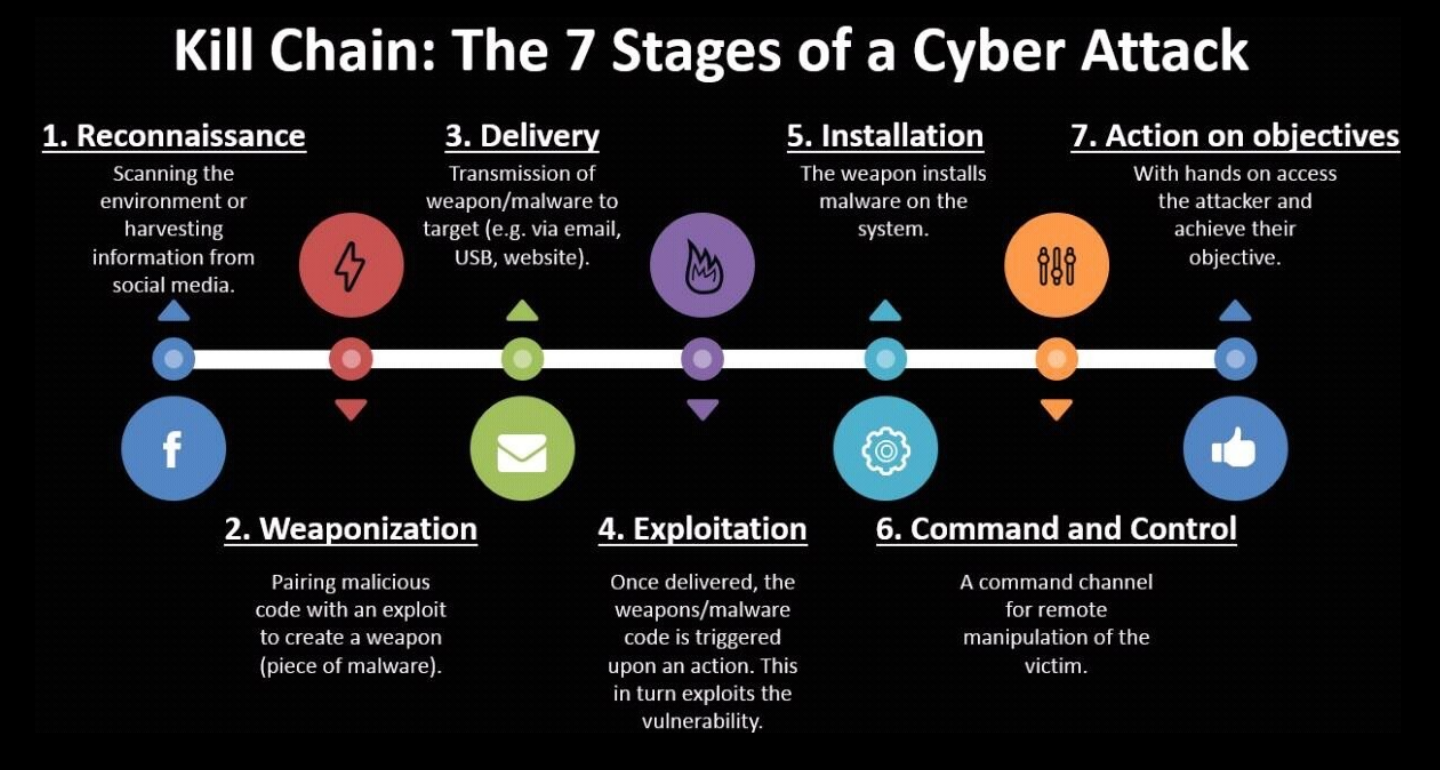
Prior Work: DL for Vulnerability Detection in IoT Devices
- [1708.06525] Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection (2017)
- Deep-learning-based approaches are now state-of-the-art in binary code similarity detection
Notable Research
- [2402.06664] LLM Agents can Autonomously Hack Websites
- Works only for closed models (GPT-4 at the time), open models could not perform
- [2404.08144] LLM Agents can Autonomously Exploit One-day Vulnerabilities
- Similar results to above
- Google Found Zero-Day in SQLite (Project Zero: From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code)
- Benchmarks like CyBench ([2408.08926] Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models)
- Solving CTF tasks
- Agents struggle to solve, but for simple tasks they solve them very fast
AI for Attacking Humans
Deep Learning can be used to empower social engineering attacks, e.g. phishing or disinformation.
- In Cybersecurity, Humans are the weakest link, i.e. common threats to most tech companies are via social engineering
- GenAI has caused social engineering attacks already
Observed Asymmetry between Defense & Offense
- Not as much operational work for defense as there is for offense
- Certain Equivalence Classes are observed, where defense capabilities are able to help attacks too
- E.g. pen-testing automation can help enable more targetted attacks, vulnerability scanning can enable attackers to find more vulnerabilities in target systems
| Aspect | Offensive Side | Defensive Side |
|---|---|---|
| Cost of failures | Only needs to find one attack that works, they have a high tolerance for failure. | Need to be prepared for everything due to potential serious consequences. |
| Remediation deployment | Can target unpatched and legacy systems using public vulnerability data, or exploit delays in patch deployments. | Lengthy and resource-intensive process, involving testing, dependency conflicts, global deployment. |
| Scalability vs Reliability | Prioritize scalability to enable large-scale attacks on a large number of targets. | Prioritize reliability, need to enforce robustness and transparency limitations. |
| Using AI | Considered a welcome method to reduce human effort and automate attacks. | Adoption is challenging as there is lack of trust in AI (largely due to unpredictability and errors) |
Consequences of Misused AI in Attacks
- Notably, the consequences are vast
- Captchas are becoming increasingly ineffective
- Voice-cloning and deepfakes for social engineering and disinformation
- Spear-phishing attacks
- Misused AI can completely change the attack landscape as it can
- help with every attack stage.
- increase attacker capability by devising new attacks.
- reduce resources and costs for attacks.
- automate large scale attacks.
- help to make these attacks more evasive / stealthy
Building Secure Systems
There are various methods to defend against such attacks, as follows:
- Reactive Defense
- Proactive Defense via Bug-Finding
- Proactive Defense via Secure-by-Construction Design
Reactive Defense
- Detect once attack happens and attempt to block
- E.g. network anomaly detection
- Using AI to improve attack detection & analysis
- Challenges:
- Attacks can use AI to make attacks more evasive
- Attack detection needs to have high TP, TN rate
- Attacks are often too fast for effective reactive response
- AI may help attacker more than defender
Proactive Defense via Bug-Finding
- Using Deep Learning for fuzzing and vulnerability detection
- Example: Google Project Zero’s Big Sleep Agent, whcih found its first real-world vulnerability recently
- Major assumption that defenders can use these systems to discover and fix bugs before attackers, which is not true (see “Observed Asymmetry between Defense & Offense” above)
- Defenders need time to develop the fix, do a lot of testing and perform deployment globally, while attackers just need to generate exploits.
Proposed Solution: Proactive Defense via Secure-by-Construction Design
- Involves architecting and building provably-secure programs & systems
- Provably-secure systems are resilient against certain classes of attacks, therefore it reduces the ongoing “arms race”
- Program Verification + Program Synthesis can lead to provably secure code with proofs
- Formally specify security properties of a system via mathematical proofs
- There already exist formally verified systems such as SEL4, IronClad / IronFleet, FSCQ, CertiKOS, miTLS / Everest / EasyCrypt, CompCert, but these are labor intensive to prove and take a lot of time
- Exploring deep learning for automated theorem proving ([1806.00608] GamePad: A Learning Environment for Theorem Proving by Prof Song, new research on Formal Math Reasoning)
- Exploring AI Agents to Prove Theorems & Verify Programs to generate Provably Secure Code
- Major considerations of the levels of automation
- [2504.11703] Progent: Programmable Privilege Control for LLM Agents - A secure Agent Framework
Conclusion
There is research being done in the domain of privacy with work done to not just detect data privacy concerns in existing models (e.g. MMDT) but developing memorization auditing and mitigating frameworks (e.g. unlearning or differential privacy) to reduce such risks. However, this work is still an open challenge worth exploring.
There is also work done in the domain of robustness, especially now with agentic systems. It is clear that LLMs and multimodal models remain vulnerable to adversarial examples, such as jailbreaks or poisoning. There needs to be work done in the alignment space to improve beyond this outcome.
AI transparency is another major domain of exploration, as current LLM systems are heavily black-boxed. There is work being done in evaluating quantitatively the internal behaviour of the models and their alignment (via representation engineering).
AI misuse in cybersecurity is escalating, as it continues to reduce costs and enable scalable, stealthy attacks on both machines and humans. Most notably, defensive adoption of AI is hampered by trust and reliability issues, and reactive defense / proactive defense via basic vulnerability isolation is not enough as offenses are cheaper, faster and more scalable that defenses. Hence, there is exploration in Secure-by-Construction program design, with formally verified systems to provably generate secure code.